Tensors basics #
Tensors stores parameters, gradients, optimizer state, data, activations. Pytorch docs on tensors
How to initialize a tensor in PyTorch:
x = torch.tensor([[1., 2, 3], [4, 5, 6]])
x = torch.zeros(4, 8)
x = torch.ones(4, 8)
x = torch.randn(4, 8)
x = torch.empty(4, 8)
nn.init.trunc_normal_(x, mean=0, std=1, a=-2, b=2)Each tensor has a rank, which is the number of dimensions.
x = torch.zeros(4) # rank 1 tensor (vector)
x = torch.zeros(4, 8) # rank 2 tensor (matrix)
x = torch.zeros(4, 8, 2) # rank 3 tensorIn Transformers, will see tensors of rank 4:
B = 32 # Batch size
S = 16 # Sequence length
H = 16 # Number of heads
D = 64 # Hidden dimension per head
x = torch.zeros(B, S, H, D)Tensors memory #
Almost everything in tensors are stored as floating point numbers
float32 #

float 32 is the default data type for a PyTorch tensor
float16 #
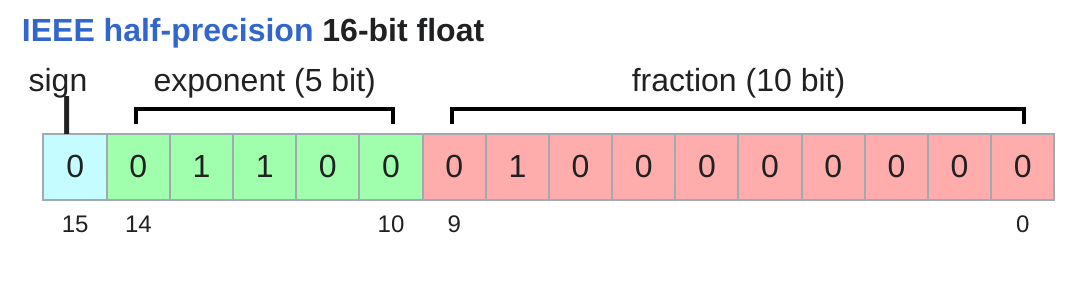
x = torch.tensor([1e-8], dtype=torch.float16)
assert x == 0 # Underflow!bfloat16 #
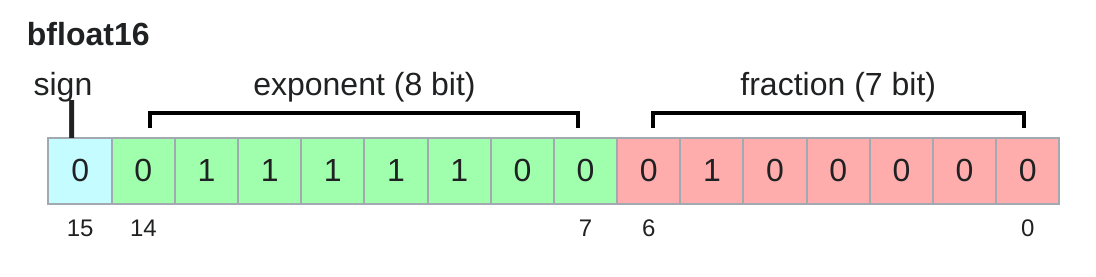
Google Brain developed bfloat (brain floating point) in 2018 to address this issue. bfloat16 uses the same memory as float16 but has the same dynamic range as float32! The only catch is that the resolution is worse, but this matters less for deep learning.
x = torch.tensor([1e-8], dtype=torch.bfloat16)
assert x != 0 # No underflow!Mixed precision #
Implications on training:
- Training with fp32 works, but requires lots of memory.
- Training with fp16 and even bf16 is risky, and you can get instability.
Solution: mixed precision training [Micikevicius+ 2017]
- Use bf16 for parameters, activations, and gradients
- Use fp32 for optimizer states
Pytorch has an automatic mixed precision (AMP) library. [docs] Tries to cast things into bf16 when safe (matmuls, not exp).
with torch.amp.autocast("cuda", dtype=torch.bfloat16):
x = torch.zeros(4, 8)fp8 #
In 2022, FP8 was standardized, motivated by machine learning workloads primer.
![]()
fp4 #
In 2025, NVIDIA developed nvfp4 Only 4 bits per value! Values: -6, -4, -3 , -2, -1.5, -1.0, -0.5, 0.0, 0.5, 1.0, 1.5, 2, 3, 4, 6 Use a separate scale factor per block, so actually get more dynamic range (but just can’t vary freely from neighbors). Nemotron 3 Super was trained in NVFP4 Some of this is done in NVIDIA libraries outside of user control.
Tensors on GPUs #
Tensors are stored in CPU memory by default.
x = torch.zeros(32, 32)
assert x.device == torch.device("cpu")
Move the tensor to GPU memory (device 0)
y = x.to("cuda:0")
assert y.device == torch.device("cuda", 0)Or create a tendor directly on the GPU
z = torch.zeros(32, 32, device="cuda:0")